In the monolithic world, doordash service only has two layers: a python Django monolithic service as the backend, and the client layer, including the web and mobile clients. The simple architecture worked well when the business and the team were small, as it enabled the product team to move fast. However it doesn’t scale as it increases the overhead maintaining the backend. A better architecture is to introduce an extra layer in the middle to decouple the front end application layer and the backend service layer so each side can move freely.
Two Layer Architecture
Let’s take a look at how the two layer architecture works first. The client interacts with the backend service through the API layer. The API relies on service modules to finish the business logic. This would work if the API layer and the service layer had a clear contract, as the service owner only needed to maintain the service modules.
Ideally, the API layer should be client oriented and product focused, while the service layer should be domain focused. For example, in the store page, we need to display information from store, menu, geo and business domains. Then there can be a store page API, which maps to the store page product. In this API, it calls store service, menu service, geo service and business service to fetch the data, and orchestrate the data to create the payload the store page needed.
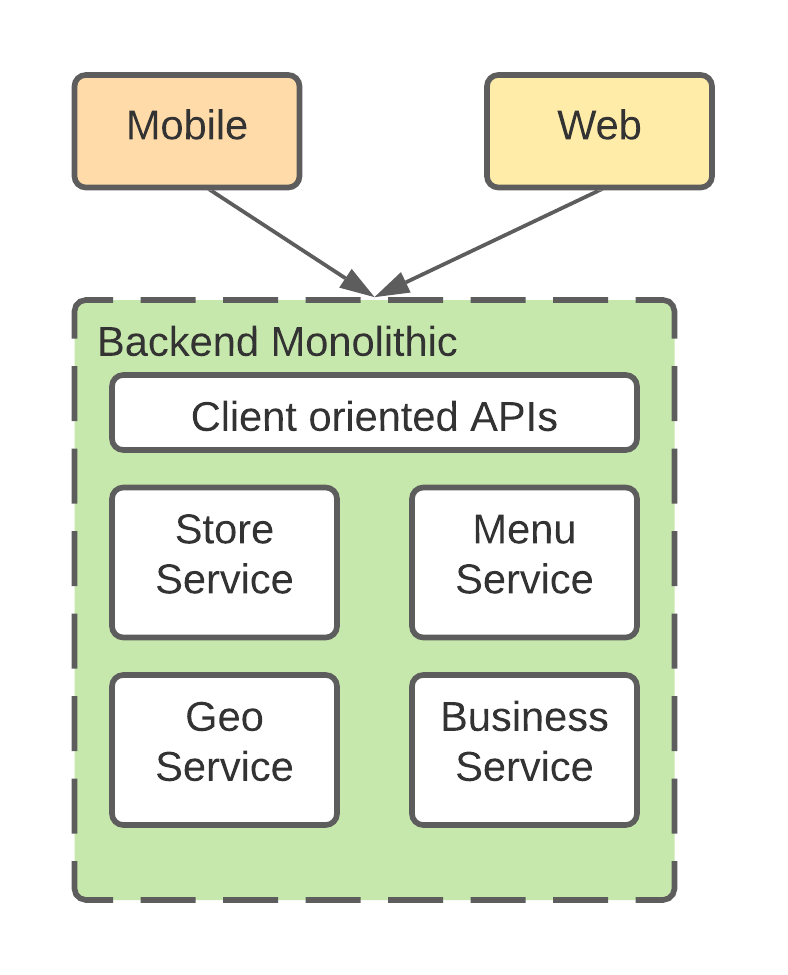
However, the above diagram was not the reality. Instead of having product APIs and domain services, the monolithic service pushed the client logic directly into the service layer and the data model layer. In this case, the service and domain models no longer have domain isolations.
Create Client Driven API with DRF and ORM
The API layer was built based on Django Rest Framework(DRF) with some extensions. The idea is very much like GraphQL: the client indicates what data they would like to have in their API request payload, and the customized DRF layer will resolve the request, and send them into the correspondent data model layers. The data model layer was based on Django Object-Relational Mapper(ORM), which will map the data fetching request into DB queries(I will explain more about the problems of ORM in later chapters).
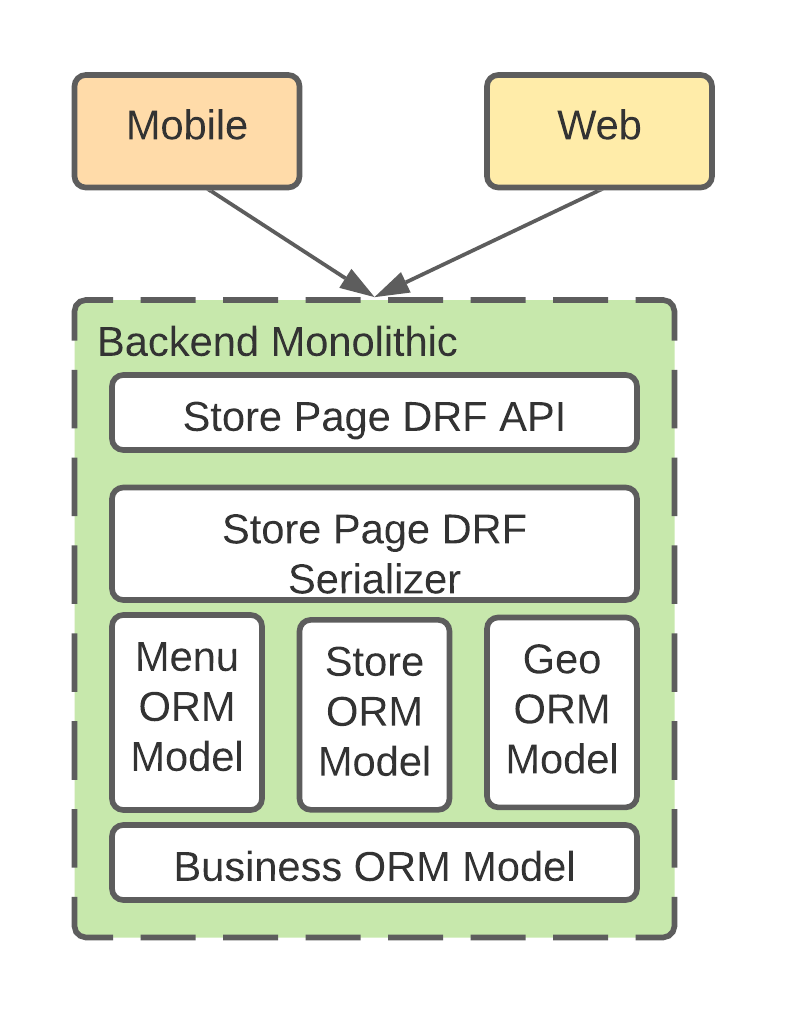
This architecture is completely client driven. The client only has to make one or a few API calls to get all the data they need, this saves their network interaction with the backend service, which can be very expensive. And the backend already orchestrates the data they need, so the client is very light-weighted. If they need to add a new data field to the API payload, they just need to add the field to the serialization layer and the data model, which can be done in a few changes.
This simple architecture creates a good product experience and enables fast iteration in client development, if the backend API performs and scales. However, this was not scalable. Now let’s take a look at the story on the backend team.
Maintenance Issues
As the product grows, there are more and more product APIs created on the API layer, they are so easy to create that the number can grow easily. And since these products are owned by the product team, the backend team usually is not in the best position to prevent this from happening.
What’s worse, as the product API iterates, the API gets more and more complex. Since the payload is fully controlled by the client, it’s hard to tell which API fetches what data at runtime: the code only tells you what can be fetched, however it does not necessarily match what’s happening in the production. In this case, it’s hard for the backend team to trace which data fetching request comes from which API.
The backend team is usually responsible for the performance and scalability of the API request. Since there are so many different API and access patterns to the data, the surface area is too large to maintain. Imagine you have 20 different product APIs, and they offer 50 different ways to access the same product data.
When you need to optimize the service performance, you often start from analyzing the access patterns, and find out the bottleneck, you will likely try to add cache, optimize the DB query, add DB indices etc. However, when you have to do this for 20 different APIs and 50 access patterns, it becomes a nightmare.
Doordash business grows fast, and there have been many times the API performance can’t support the traffic growth and a SWAT team was created to optimize the performance. It was effective, however, not sustainable. These ad hoc fixes don’t change the development scheme, as the product and service growth, the same problem will happen again.
What Backend Team Wants
In an ideal world, the backend team would like to have a clear contract between the client and the backend, each team should only focus on only a small interface area. There should be clear service boundaries between domains and predictable access patterns to the data, so that the backend team has the freedom to make decisions in their own realm.
There are many ways to solve this problem, even in the monolithic world, it can be done by defining a clear boundary between the product layer and backend layer. One of the solutions in the microservice world is to introduce a middle layer: backend for frontend(BFF).
Backend for Frontend
The backend for the frontend layer is a thin service layer that sits between the client and the backend layer. On the client facing side, it provides comprehensive APIs to simplify the client to backend interaction. On the backend facing side, it integrates with the backend through the doman APIs. The BFF layer is now responsible for resolving the requests from the client, and map them into the backend APIs and do the data orchestration.
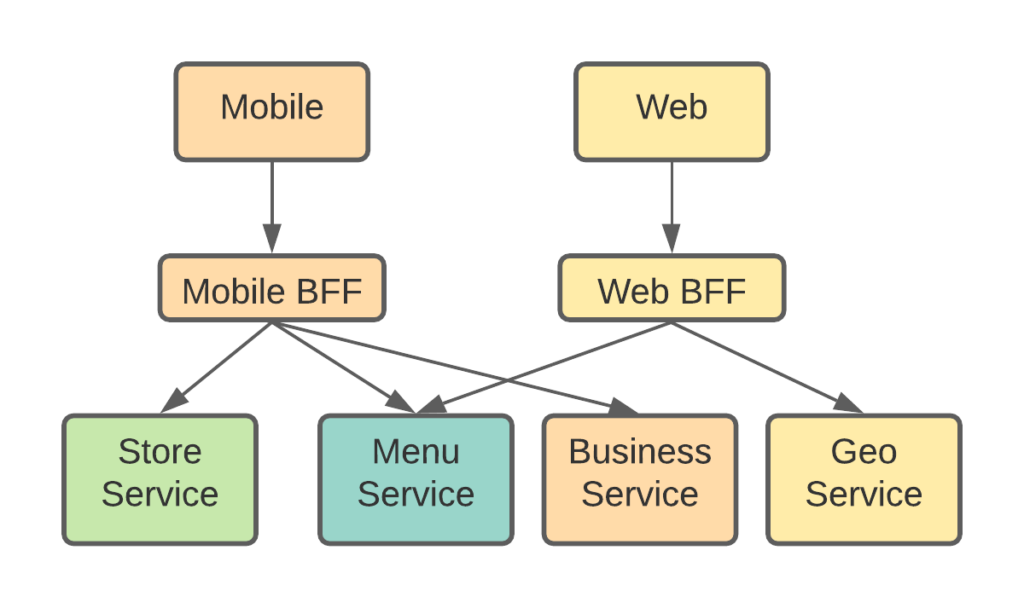
The BFF layer can be implemented in a language that the product team is more comfortable with, such as Node.js + GraphQL.
The BFF architecture is a win-win solution for both the product team and the backend team. The client team wants to focus on building a great product experience, and worry less about the backend data integration logic. This architecture enables them to keep focused, and have the flexibility to change the interaction pattern in a language that they are familiar with. The backend team can have more isolated domain service and less APIs. They can stay forced on optimizing and scaling their domain APIs. They can now control how the data is accessed, and have a clear picture about the access pattern and performance of their APIs.
What’s the cost? The cost of this solution is that you will have one more layer to maintain, and each API call has to go through two hops instead of one network hops. To resolve this issue, you need to keep your BFF layer thin, except for data orchestration and API call mapping, you should not try to put business logic into it. The backend team should focus on optimizing the APIs so that the overall API call performance is no worse than the two layer architecture. And from our experience, this isolation did bring much way more performance gain end to end than the cost of the extra hop.
BFF Helps Service Extraction
Besides, the BFF architecture also helps the service extraction. During monolithic service decomposition, one of the biggest challenges was how to keep the migration un-interpretative for the clients. You can create backward-compatible APIs and ask the client to migrate over, however, 1) mobile clients usually releases much infrequent than the backend service, the migration will slow down inevitable, 2) the backend team can’t control the rollout pace since they don’t have the knowledge of the client code: testing, development, release, and aligning the migration timeline with a resource contention client team can he very challenging.
Introducing the BFF layer means the API migration can happen in a backend service rather than the clients. It means the migration can happen at a much faster iteration speed and in a domain the backend service is familiar with. And as we will see in later chapters, the ability to finish the migration faster is one of the most important considerations during service extraction.
About This Blog Series
This post is part of the “How to split a monolithic service?” blog series, check the introduction for more details: How to Split A Monolithic Service? Introduction