Database is oftentimes the bottleneck of service scalability and reliability. Between 2018 and 2020, Doordash experienced multiple site wide outages during our traffic peak hours due to database issues. Before we are able to break down the monolithic service, we need to put off the database fires to ensure the team has enough room to focus on the service extraction. In this chapter, I am going to introduce how we scale the SQL databases.
Why is scaling SQL DB difficult?
Because of ACID constraints, SQL databases are usually harder to scale when compared with NoSQL databases. As the business grows, both the data and the traffic volume to the database will grow. While it’s comparable to easy to scale DB reads, it’s hard to scale DB writes, as it usually involves some format of partitioning.
Scale Up
The fastest way to scale the SQL database is to scale up by upgrading your hardwares, more CPUs means your DB server can process more queries at the same time, bigger RAM means more data can be processed in the memory instead of having to fetch from the disk. However, there is a limit to the hardware you can upgrade, and you can use it up very quickly.
Optimize DB Queries
Next you should consider optimizing your DB queries, including full table scan, slow writes etc. You can start from the biggest database and the hottest tables. There are almost always some long hanging fruits. You may use SQL DB analyze tools such as PGAnalyze or SQL explain command.
Usually these slow queries can be fixed by:
- Adding index to the where/on columns to speed up the writes.
- Removing unused columns to reduce the query payload.
- Break expensive join queries into individual queries and move join operation to server side.
- Denormalize database schema to reduce the number of tables involved in the query.
- Create an extra table to save the results for expensive queries such as full table scan.
- Other means such as adding cache will be introduced later.
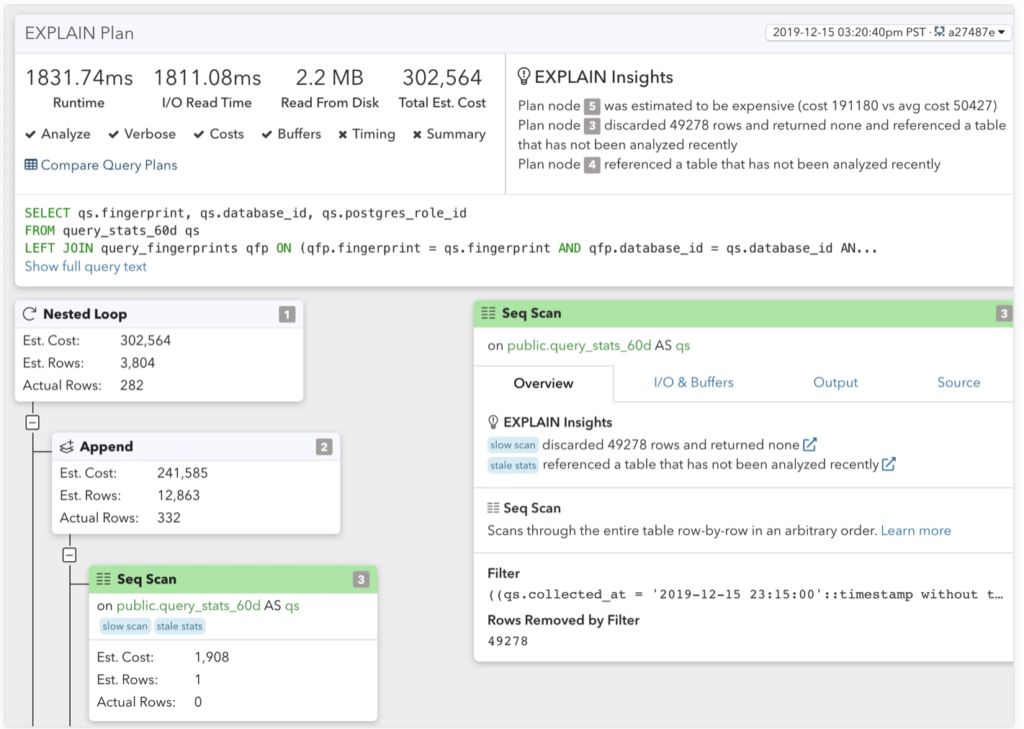
Add Read Replicas & Balance the DB traffic
An easy way to scale read is to add read replicas, but you should make sure you balance the load between the replicas. Adding replica instances can often be done automatically today, it can significantly reduce the average DB load, and since the read is averaged out to different replicas, the memory consumption at each instance is reduced, and hence each db instance can host more data in memory, so the benefit is usually more than linearly.
Most of the time, the traffic to DB instances is skewed: too much traffic goes to the primary instance, and some replicas take more load then others. To balance the load, you can do it in your application or do it in your SQL server.
To make sure the application has enough flexibility to choose which instance to use, for example, use primary instance during write queries, and use replica instance during read queries, you often have to expose the connection to different instances in the application code. You can implement a simple random allocation algorithm to make sure the read traffic is balanced. You might also use server side load balance technologies such as PGPool or PGBouncer for your PostgreSQL DB.
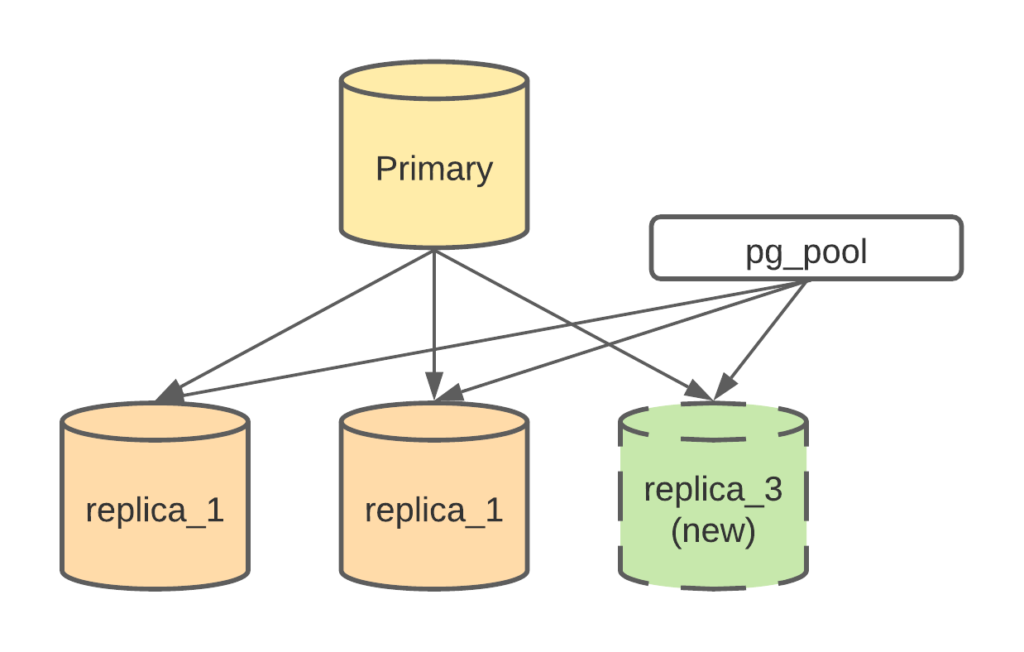
Add Cache to Reduce DB Query Load
Another effective way to reduce the DB read load is to add cache to your DB queries. There are many ways to add cache, the choice really depends on your application scenario. One most commonly used cache is the write through cache. Write through cache is to update the cache when you update the data. While it sounds simple, it can be tricky. I am going to introduce the cache issues in our monolithic service and how to avoid them in our new microservice in later chapters.
Reduce DB table size
Database size matters. Database size grows inevitably, you will end up having more tables, with each table more records and much bigger indices. When db size grows, the RAM may not be able to host the data records and the indices. Even with more CPU, it would not help, as the CPU will have to wait for IO operations, such as swapping data with the disk when there is not enough memory. Smaller tables help. Small table means the data has a higher chance to be stored in memory.
To reduce the DB size and table size, one way is to partition the database, which I will talk about later, or remove the dead records or archive the historical records. It’s usually hard to determine which records are dead, however a safer option is to archive the inactive records into another table to reduce the online table size. The archived table can still be accessed by the applications, you may need to refactor your database queries to fallback the query to the archive table when you can’t find the record in your online table. Since the archive table is usually not optimized, you should try to avoid such access as much as possible.
Partition Vertically
Partitioning vertically simply means you move some tables to other db instances. In doordash’s monolithic world, the majority of the tables live in a main db instance. This enables easy cross domain data access however not scalable.
To reduce the db size, you need to identify the domain boundaries, remove the forign key dependencies, then move the table into another database. This also helps break down the monolithic service into domain services.
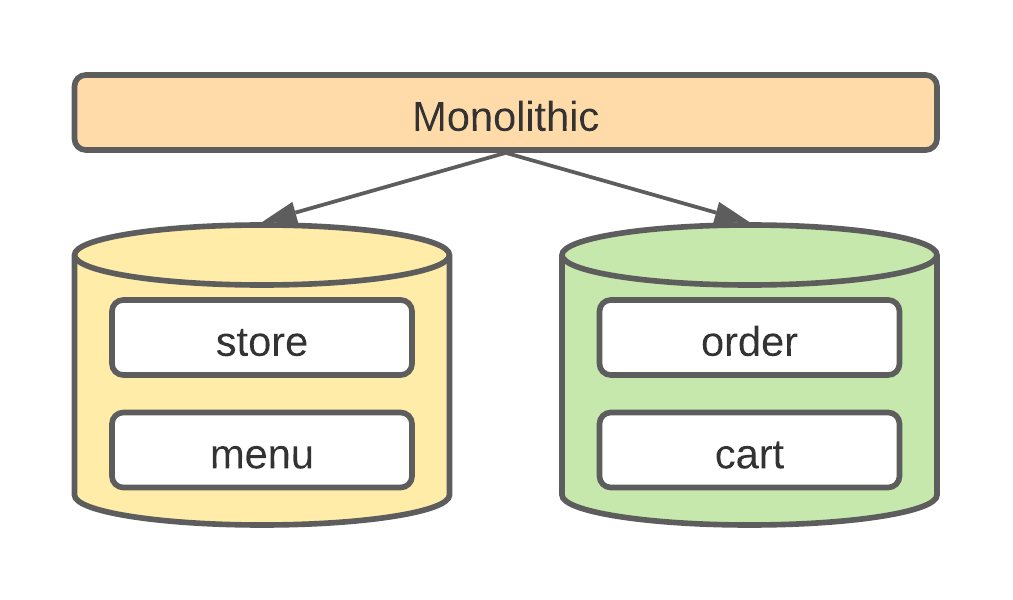
Partition Horizontally
Partitioning the database vertically reduces the overall db load, however it doesn’t help when one table becomes too large for one db instance. This time, you should consider partitioning the table horizontally. Horizontal partitioning is much harder, as it usually involves database architecture change as well as major code refactoring. I will talk about horizontal partition in a separate chapter.
Other Approaches
Beside the approaches mentioned above, you should also consider building connection pooling, middleware such as pgbouncer is very helpful in these cases. You can also consider migrating your SQL database to a more horizontally scalable database, such as NoSQL or NewSQL.
About This Blog Series
This post is part of the “How to split a monolithic service?” blog series, check the introduction for more details: How to Split A Monolithic Service? Introduction