Cache can help reduce the load to the database and improve the service performance, however, designing and using the cache in the optimal way is one of the most tricky problems. In Doordash’s monolithic world, there were many anti-patterns cache usage, which makes cache itself a scalability issue. In this chapter, I am going to revisit the bad practices using cache, and discuss the right principles as well as some interesting cache problems.
Avoid N+1 Cache Access
As discussed in the previous chapters, the Django python service uses ORM heavily. On top of the ORM DB access, we also introduced a cache layer, where people can cache their query results easily in the Redis cluster. And when users try to read the data through the ORM model, it will access cache data first. While this seems reasonable, the query performance degraded severely during traffic peak due to N+1 cache access problem.
ORM query creates an illusion that accessing the data is as easy as accessing them from the memory. Consider the following example:
menu = Menu.objects.ge(id=123)
for item in menu.items:
name = item.name
...The above code will end up querying the cache or database N + 1 times. The 1 time is to fetch the menu object, while the N times is in the for loop to fetch the menu items. ORM do lazy loading, so when you call menu.items, it doesn trigger a one time load for all the items related to the menu, instead, only when you try to access the individual items, it will load them one by one from the cache/db. That means the code ends up accessing the cache/db N + 1 times, which is very expensive.
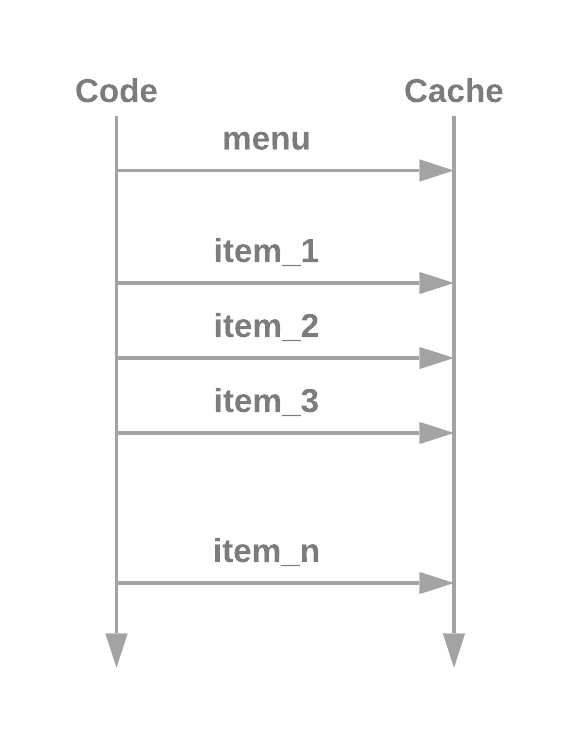
Fetching one record from the cache is very quick, might take only a few milliseconds, however, when you have to fetch data for N times the cache access becomes a significant part of the query. To solve this problem, one way is to batch fetch all the data you need from cache in one request. For example, the mget query provided by Redis.
Randomize Cache Eviction
Most of the time we add a TTL to the cache, even for the write through caches. This is to prevent persistent stale cache. However, you should be careful when you set up the cache expiration date. As if the caches TTL are reset at the similar time, they will also expire at the similar time, and bring extra load to the service. One solution is to add random TTL to the cache so their expiration time can be evened out.
Avoid Cache Miss Storm
The cache is usually accessed by multiple services from multiple requests simultaneously, when they are requesting for different data, it’s usually fine, however if there happens to be a hot data record, cache miss can cause a load storm on the database. When cache misses, the request will fallback to the database. The cache will be refilled after data is fetched from the database. There is a delay in between, and all the requests might fallback to the database at the same time.
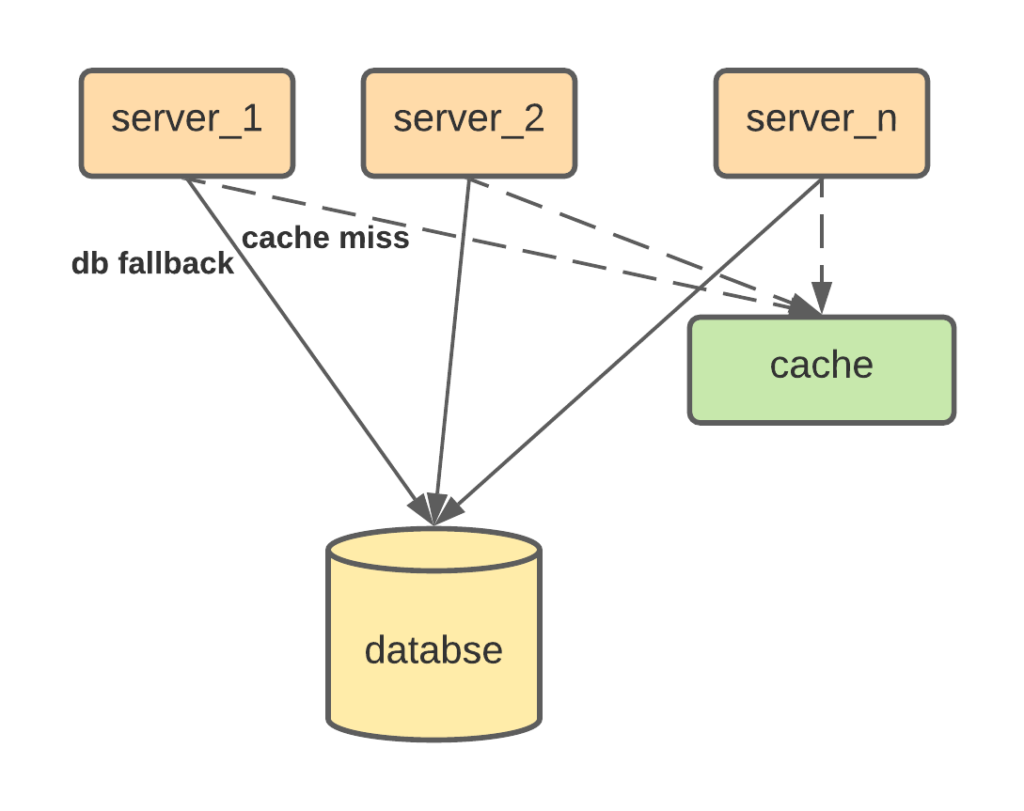
One way to prevent this problem is to allow only one request to fallback to the database, while the other request should hold and wait for the request to finish and refill the cache. This can be implemented in many ways, one way is Facebook’s memcache lease solution.
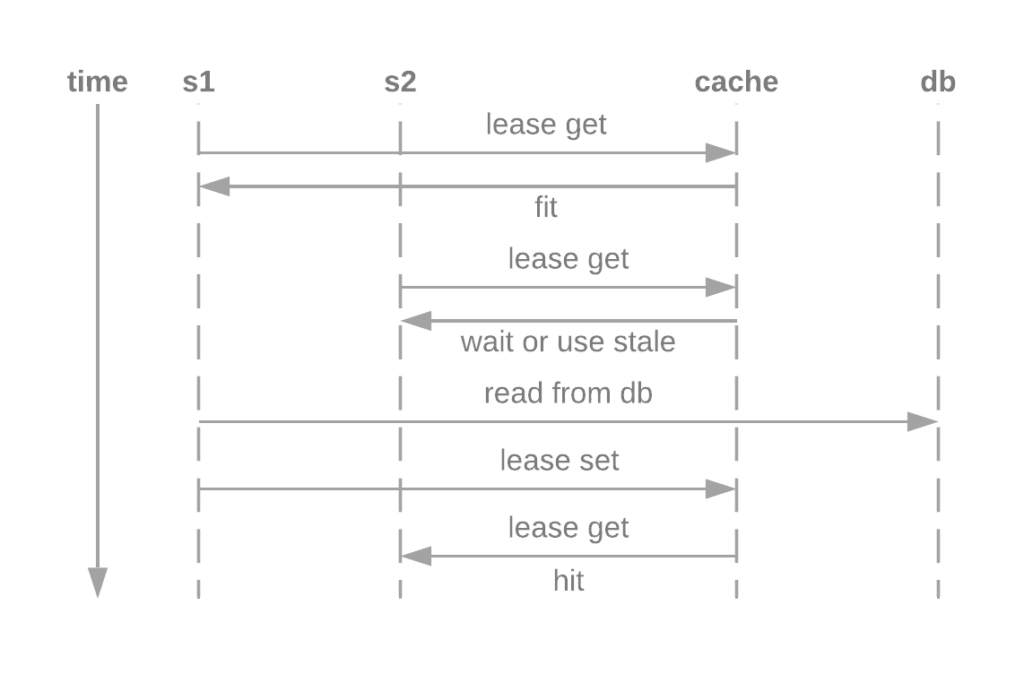
In this solution, the first request will get the lease from the cache, when other requests try to get the same cache, the lease is empty and the request has to hold or use stale data. When the first request is processed, the lease will be returned and the other requests can proceed.
Avoid Scattered Cache
In doordash’s Django monolithic service, cache data was scattered in small pieces, so that it’s almost impossible to understand what is cached while what is from the database. This created lots of challenges for troubleshooting, as there is no easy way to reproduce the data issue.
The scattered cache data were due to the abuse of cache annotation and cache middleware. For example, a python annotation @cache was invented that the function result can be automatically cached and retrieved once the annotation is added to the function. The lesson we learnt was we tend to abuse what they can get easily because we don’t really realize the cost of them.
Access Cache Explicitly
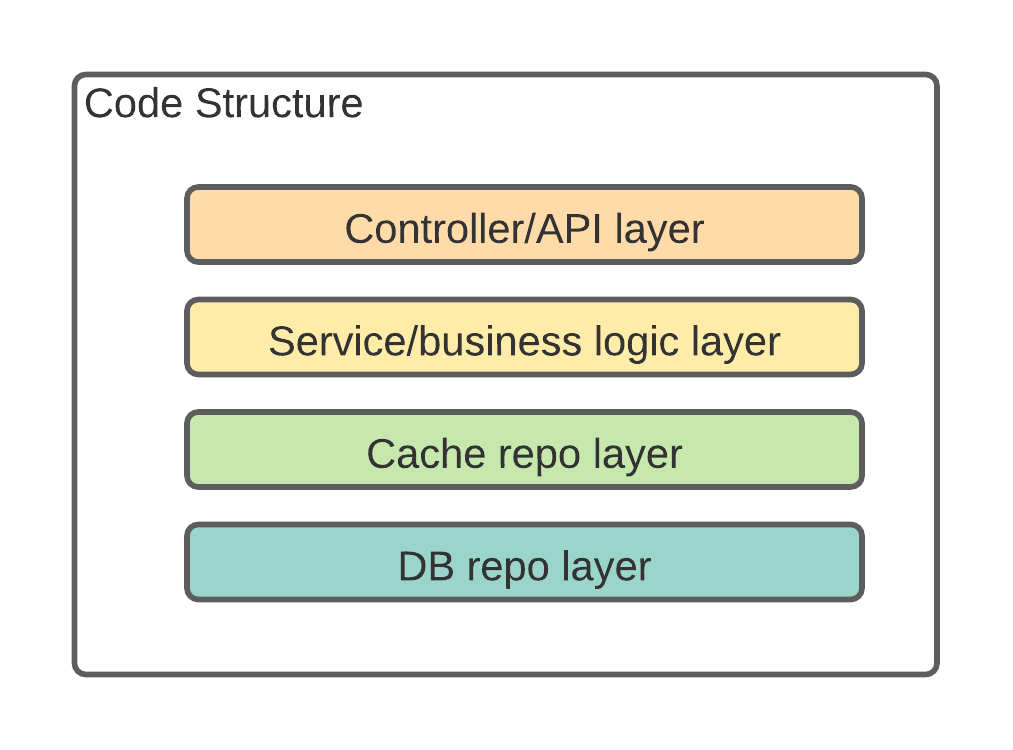
To avoid the issue mentioned above, we decided to limit the number of cache we will use, and make cache an explicit layer that is different from the db layer, and everytime the request accesses the cache, the cache layer functions have to be called explicitly. In the coding practice, we created a separate interface for cache, and a repository class to call out that this is a cache repo. This improves our developer’s awareness using cache, the key is to remind all of us that cache comes with a cost, in both service performance and service maintenance.
Cache DB or Cache Request
When designing cache, one major question is: what to cache. You can either cache the request data, which enables you to fetch the request result from the cache and return without having to compute the data. If you are using write through cache and require the cache to be as fresh as possible, you have to regenerate the cache whenever any relevant data is updated. This can cause quite a high cache eviction rate and your write path has to understand the behavior in the read path, which increases the coupling.
Another issue is, you might end up creating many pieces of cache for different requests, which makes it much harder to maintain. This works when computing the requested data is very expensive, you have a relatively limited access pattern in your read path, and read is the dominant traffic compared to write.
Another option is to cache the database data. In this option, your cache data model is very close to your database model. The benefit is you have a very simple cache update logic: whenever the database data is updated, the cache data should be updated. Your request however will have to compute the request again. And this enables you to decouple the cache write from the cache read. This solution works when the request generation is cheap and you might have many different types of requests.
Cache Consistency Cross Data Center
The last topic I want to talk about is the cross data center cache consistency. Distributed cache is limited within the data center, since cache is very sensitive to network latency, the round trip delay between data centers will defeat the purpose of creating the cache. However, databases are usually replicated across data centers, which will create the following architecture.
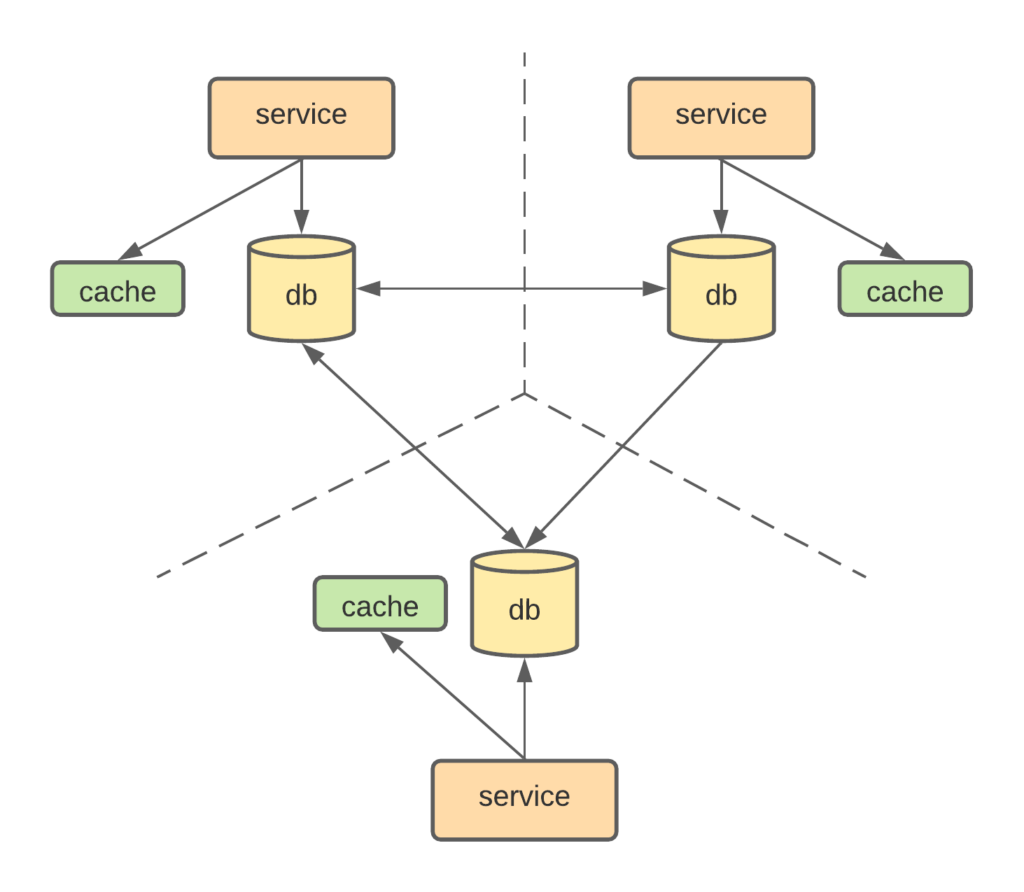
The issue is, when the service updates the cache, they only update the copy locally, even though the database is replicated over, the service in another data center might still get a stale copy from their own cache. To solve this problem, one solution is to rely on the database update stream to update the cache instead of relying on the service to write the cache through. The implementation is much more complex since you have to access the database commit log.